Pranav Saxena
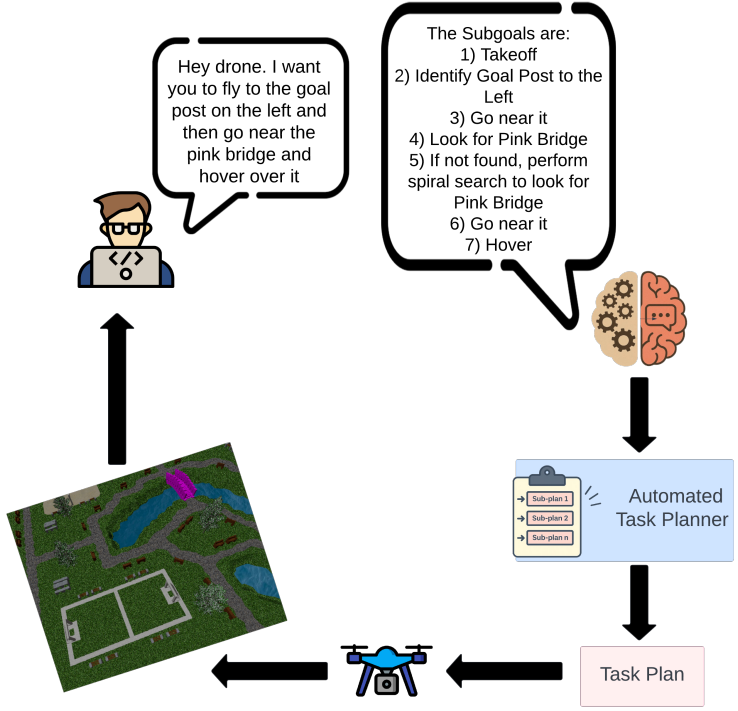
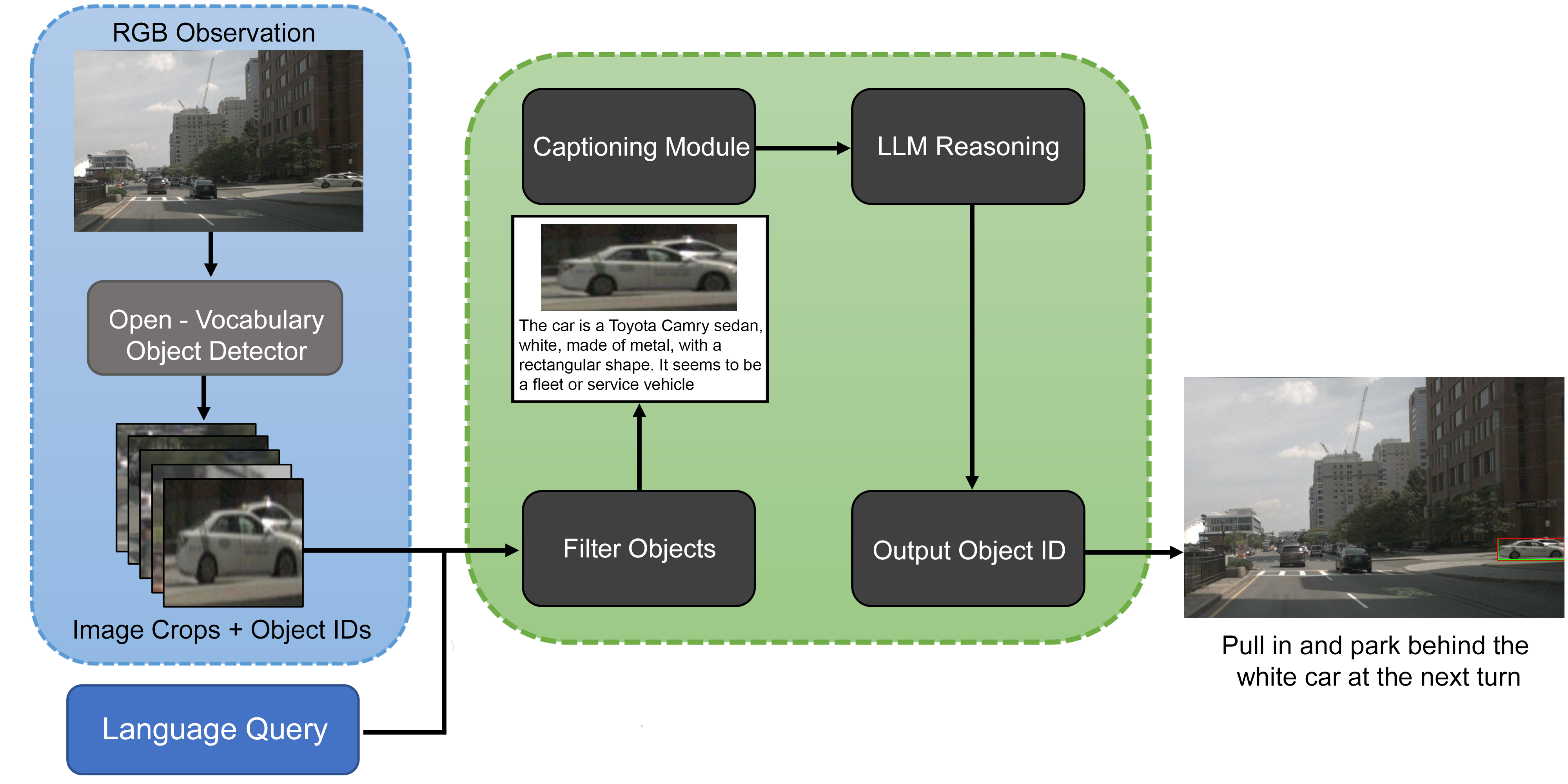
Hi! I'm Pranav, a senior in ECE at BITS Pilani, Goa, India. I'm interested in 3D Computer Vision, 3D Scene Understanding and Multi-Modal Generative Modelling. Currently, I'm at Carnegie Mellon University's Robotics Institute pursuing my undergraduate thesis under the supervision of Dr. Wenshan Wang at AirLab and Dr. Ji Zhang. Here, I have worked on Vision Language Navigation in Outdoor Scenarios and I am currently working on 3D Object Representation Learning.
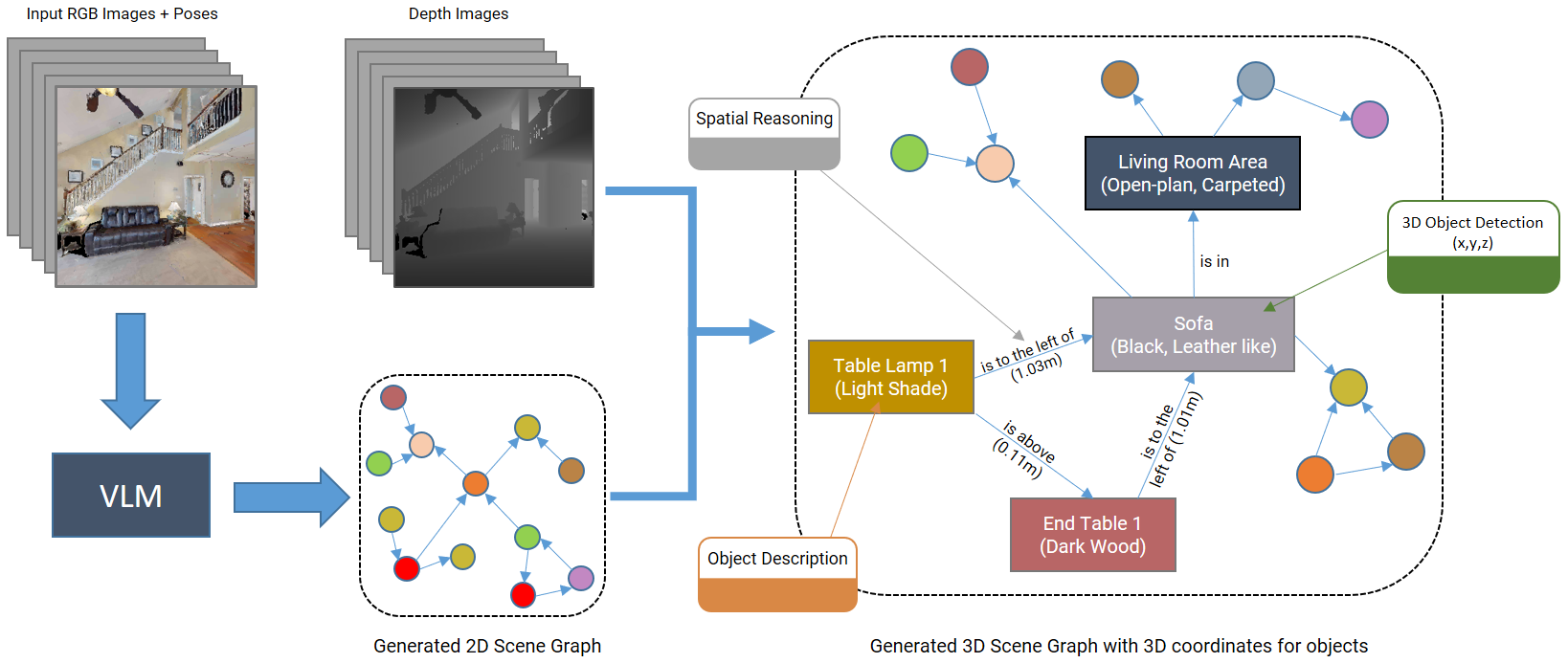
Since my sophomore year, I have also been remotely working at MARMoT Lab, NUS under the supervision of Prof. Guillaume Sartoretti. Here, I have worked on 3D Scene Graph Generation using VLMs, Next-Best-View Policy for NeRFs (co-supervised by Prof. Marija Popović), Open-Vocabulary Gaussian Splatting.
At my university, I am grateful to have worked with Prof. Neena Goveas, Prof. Naveen Gupta, Prof. Sarang Dhongdi, and Prof. Tanmay Tulsidas Verlekar.
Beyond academics, I enjoy watching series, movies, travelling and playing sports. I also love tinkering with drones, and I founded an autonomous drone team in my sophomore year ;)